PMD 7 is here (finally)
We are proud to announce PMD 7.0.0: a new major release of PMD.
After more than one year after the last stable release 6.55.0 and after 4 release candidates, the new major release of PMD is finally ready and released. This was a big effort and many things have been changed and improved. This blog post will go into a bit more detail on the changes.
Many thanks to all users and contributors who were testing the release candidates and provided feedback and/or PRs!
The binaries are available on GitHub releases: https://github.com/pmd/pmd/tag/pmd_releases%2F7.0.0 The documentation is available here: https://docs.pmd-code.org/pmd-doc-7.0.0/
What is PMD?
PMD is a static code analyzer, that was created in 2002 to help find common problems in Java programs. The meaning of the abbreviation “PMD” is not entirely clear, but software archaeology studies show up a package-info.java, which originated from a file package.html which originated from commit 6c8ad793 from August 2004. This suggests, that PMD actually stands for “Programming mistake detector”. IMHO, that’s a very good summary.
PMD started off as a rule-based static code analyzer for Java with many provided built-in rules. It was eventually enhanced to support multiple different versions with PMD 5 and we keep on adding support for additional languages since then.
While Java was already the best supported language in PMD with type resolution and symbol table, it was completely revamped with PMD 7 to even provide better type resolution and symbol resolution. Including Java, PMD supports now in total 16 languages, for which built-in rules are available or can be written.
Another functionality that PMD provides is finding duplicated code through its Copy-Paste-Detector (CPD). This is supported for even more languages - 34 in total.
One key point of PMD is, that you can enhance it by writing custom rules. This is made even easier, by providing the possibility to write the rule as an XPath expression querying the AST of the code under analysis.
Besides this core functionality, there is a UI tool that helps to write custom rules, the PMD Designer. And PMD is integrated in various build tools such as Maven or Gradle, and in various IDEs like Eclipse, IntelliJ IDEA or Visual Studio Code.
What’s new in PMD 7?
The most obvious change is the new logo of PMD. You have probably seen this already, since we switched to the new logo a while ago:
The new logo is neutral, doesn’t limit the direction of PMD’s future and, most important, it is not offensive or glamorizes violence. In the end, PMD tries to help developers.
PMD 7 brings updated support for the Java language, most notably it can parse the new language constructs of Java 21 and Java 22, such as JEP 440: Record Patterns, JEP 441: Pattern Matching for switch and JEP 456: Unnamed Variables & Patterns. Under the hood, that Java module got a complete revamp, which is described in more detail down below: Revamped Java Module.
The Apex language support also got a very interesting update. The Apex language is a custom language used in the Salesforce Platform and PMD is quite a popular static code analyzer for that language. More on this down below: New Apex Parser.
With the implementation for full support of Antlr grammar, language modules in PMD can now be based not only on JavaCC grammars, but also on Anltr. This opens up the opportunity for new supported languages such as Kotlin or Swift. More on this down below: Full Antlr support.
Another rework was done on the command line interface. The new CLI is more unified between the different supported commands, supports auto completion and we even have a progress bar now. More on this down below: CLI and progress bar.
A major version provides the opportunity to introduce breaking changes and cleanup old stuff. That’s what we did in the epic PMD API evolution. This is mostly only relevant for tool integrators such as build/IDE plugin developers or power users, who write custom rules. More on this down below: API rework and NodeStream.
And there are many more changes shipped with PMD 7, like support for new languages (Coco, Julia, TypeScript) for CPD and many bugfixes to rules. You can read the complete release notes in PMD’s documentation page: Detailed Release Notes for PMD 7.
Revamped Java Module
PMD maintains its own JavaCC based grammar for the Java language. This grammar defines, what a valid syntax looks like for Java programs and more importantly, how the AST (Abstract Syntax Tree) is structured: Which nodes are defined, how they relate to each other (e.g. whether there are common super types) and how the source code translates to these nodes. This is always a bit of a trade off: The AST should be abstract enough, so that it can be used in a simple way to analyze and query it, but it must be at the same time detailed enough, to correctly represent all information from the original source code.
The Java language also evolves and new language constructs are added over time. In PMD, we therefore need to update our grammar as well, so that our generated parse can understand the new Java language constructs that were added since PMD was created - like annotation, generics, and the new different types like records, sealed classes or patterns. The grammar of PMD 6 was in some areas incomplete, e.g. our grammar wouldn’t allow annotations in specific locations, such as annotated generic types or arrays. This has been fixed with PMD 7, so that we can now also parse programs with these edge cases. Furthermore, we refactored the grammar partially, so that we are more aligned to the official standard, that defines the Java language: the Java Language Specification (JLS). The JLS actually defines the grammar, which we try to reuse if possible.
Changing the grammar however is often a breaking change. E.g. if you rename nodes (which are productions in the grammar), then this breaks every rule, that uses these nodes. While adding new nodes can sometime be done without breaking compatibility, renaming definitely not. That’s one reason, why we did this in a major release. This of course has the downside, that every Java rule needs to be adjusted to the new grammar AST. And this is true, regardless whether the rule is written in Java or is a XPath rule. For the built-in rule, we did this already, updated every rule and made sure they work as before - or even better. On the way to update the rules, many bugs could be fixed, so that we have less false positives and false negatives. There is a whole chapter about the AST changes for Java in the Migration Guide for PMD 7.
The reworked grammar now provides also more semantic abstractions: While we before had e.g. just a Name node, now we use the nodes FieldAccess, VariableAccess and ArrayAccess which provide already more information. Note, that in the source code, often these different nodes look the same: They are just an identifier. In depends on the context, whether this specific identifier identifies a field, a local variable or an array. See JLS §6.5 for the details. In PMD, this is implemented in a multi stage approach: First, the identifiers are parsed as ambiguous names and in a later processing stage, these ambiguous names are replaced by their correct node type. This is partly done during parsing, when it is clear already by the syntax, as explained in javadoc of ASTAmbiguousName). Or it is finally resolved in a separate AstDisambiguationPass.
This means, that building the AST for Java is not just executing the parser. There are multiple passes necessary, see JavaAstProcessor#process. This is important to know, if you want to add a new language to PMD with all the same features like Java has: It is much work, hence our disclaimer on the instructions on Adding a new language (JavaCC) or Adding a new language (Antlr).
One of these additional passes is Type resolution, which also got a complete rewrite for PMD 7. The most important change under the hood is, that we don’t rely anymore on Java reflection to analyze code. In the past, that meant, that you needed to run PMD with a Java runtime equal or newer as the software project was using to compile - as PMD loaded the compiled classes into the running JVM and inspected the available methods etc. via reflection. PMD 7 now uses ASM to just load the bytecode and analyze it without loading the classes into the JVM. This means, it only depends on the version of ASM, whether PMD can understand the bytecode - so theoretically you can run PMD now with Java 8 and analyze a project, that uses Java 21 without problems. Since the application probably uses classes and interfaces of the Java API, it is now important to provide the correct auxiliary classpath, so that PMD can find the correct definition of e.g. java.util.List. PMD 7 now supports finding classfiles not only in jar files, but also in modular runtime images via the jrt:// filesystem. The usage is explained in PMD’s documentation for the Java Language: Providing the auxiliary classpath.
The implementation of type resolution in PMD is centered around the interface JTypeMirror. It represents a concrete type and provides access to super types or declared or inherited methods. You can get such a type mirror from any TypeNode by calling the method TypeNode#getTypeMirror(). In rules, you often want to check, whether something is of a specific type; this is covered by the methods of TypeTestUtil.
For method calls, the types subsystem also performs an overload selection, to figure out, which method exactly is being called. This information is available via ASTMethodCall#getOverloadSelectionInfo(). The returned object OverloadSelectionResult gives access to the declaring type, the return type and so on. This is available via JMethodSig which represents method signatures.
The type resolution system is closely connected to the new symbol table implementation: JSymbolTable. This has also been rewritten completely for PMD 7. The symbol table can be retrieved on any Java node by calling getSymbolTable(). The returned symbol table provides access to the methods, types, fields, variables, that are in scope.
A simple usage resolution is available for local variables, e.g. via ASTVariableId#getLocalUsages(). This returns a list of ASTNamedReferenceExpr, which you can query for the access type, whether it’s read or write access. The returned named expressions are actually ASTExpression. In other words, if an expression references a name, then it is a ASTNamedReferenceExpr and you can get the referenced symbol with getReferencedSym() from which you can get access to the declaring node via tryGetNode(). By the way: the nodes ASTVariableAccess and ASTFieldAccess are such ASTNamedReferenceExpr, so you can easily navigate from a variable usage to the declaring node.
Symbol Declaration nodes, such as ASTVariableId provide also access to their symbol via getSymbol(). From the symbol, you can call tryGetNode() which gives you access to the declaration node in the AST. The symbol is the same, that you can get from the symbol table or from the variable access. So you can navigate from either side.
There is no utility class yet to make easier use of the symbols, but you can have a look at the internal utility class (which is not public API and might change): JavaAstUtils.
Overall, this was a very huge effort, involving almost a complete rewrite of the Java module. The new implementations are better than ever. I guess, we’ll learn now, how this new capabilities can be utilized in concrete rules. If we find any shortcomings like missing functionality, ease-of-use issues, we’ll be happy to fix them.
A big shout-out to Clément Fournier (@oowekyala), who over the course of the last years worked on this rewrite, along with Juan Martín Sotuyo Dodero (@jsotuyod) and Andreas Dangel (@adangel).
New Apex Parser
This was another long running effort, that started already 2 years ago in 2022 with issue #3766 on GitHub. Apex support was added with PMD 5.5.0 in 2016. At that time, 8 years ago, there was no open source parser for Apex Code available, that worked reliably and was kept updated with the current Apex language development. As with any language, Apex adds new features as well from time to time, so that parser needs to be kept up-to-date, in order to be able to analyze modern Apex code.
At that time, we made the decision to integrate a closed source parser, that was part of the language server for the Salesforce Extensions for VS Code, whose name is Jorje. This library was provided by Salesforce kept loosely up-to-date. Since it came from Salesforce, it was expected, that this library basically defines, what is valid Apex code syntax. This means less doubt on our side in terms of grammar and parsing.
The integration in PMD worked by creating an adapter, that makes the internal AST nodes provided by Jorje available as PMD AST nodes. Once that was done, all the features like rule execution and XPath rules, work as with any other language. The JavaScript language module uses a similar approach - here we adapt the AST nodes of Rhino.
However, since this library is just a blob of classfiles bundled into a big jar with all dependencies merged and/or shaded, it was very difficult to understand, what exactly has been updated, which dependencies are actually required. And since, the blob contains more than what we need (it is part of a language server implementation), we tried to remove as much as possible, but weren’t never sure. It was much guesswork. Including, when we updated the library: What is actually new? The easiest way was always to try and see where it fails…
Thanks to Aaron Hurst (@aaronhurst-google), who started and led the initiative to move to a fully open-source parser, this is now fully implemented. The solution consists of multiple pieces:
- apex-parser by Kevin Jones (@nawforce). This is the grammar itself, which is using Antlr.
- Summit-AST is a library, that translates the parse tree of the apex parser into a more abstract tree, usable by PMD.
The Summit-AST library has been written fresh exactly for the use case in PMD - the produced AST is structured very close the AST that the former Jorje parser created. This means, that existing rules most likely won’t need to be adjusted, despite the fact, that the complete parser implementation has been switched. The few cases are documented in the Migration Guide for PMD 7: Apex AST.
With PMD 7, we support now two new language constructs in Apex:
- User Mode Database Operations (Winter ‘23)
-
Null Coalescing Operator
??(Spring ‘24)
Full Antlr support
This project was started in 2019 by ITBA students Lucas Soncini (@lsoncini), Matías Fraga (@matifraga) and Tomás De Lucca (@tomidelucca). PMD 6 supported only JavaCC-based grammars. Antlr was used only for CPD, which just requires a tokenizer and no parser. But in order to support our rule engine and XPath based rules, a better integration of Antlr was needed.
With PMD 7, a new language module can now be implemented based on an Antlr grammar, similar to JavaCC-based grammars. The process is described in the guide Adding a new language (Antlr). Antlr is used to generate the parser from the grammar. This is integrated into the build process. Then additional infrastructure code is required, to make the parser available for use by PMD and rules, like a language handler, adapter for nodes and base classes for rules.
Thanks to this addition, PMD 7 now supports the languages Swift and Kotlin. These language modules also provide some built-in rules ready to use.
While the basic implementation for Antlr support is done, there is more work to be done. The Antlr parser produces initially a so-called parse tree. Currently, PMD is using this parse tree directly as the AST structure, that is exposed to rules. This makes these two languages a bit clumsy: There are many nodes, and each token is also represented as a node. This is of course a very detailed and correct representation of the parsed source code, but not yet what you’d expect to be an abstract syntax tree. That’s why the Apex module added an extra step with Summit-AST to translate Antlr’s parse tree into a more abstract syntax tree. A good explanation for parse trees vs. abstract syntax tree can be found on stackoverlow: What’s the difference between parse trees and abstract syntax trees (ASTs)? That’s definitely an area, where PMD can be improved, providing easy to use infrastructure code to perform this translation.
CLI and progress bar
PMD 7 ships with a completely revamped command line interface. Before that change, we had a very asymmetric implementation for our start scripts: For Linux/Unix based systems, we had a shell script called “run.sh” which could launch all the different utilities of PMD, like PMD itself or CPD and the designer. For Windows however, we had a couple of different batch files, one for each command.
This is now rectified: We have a shell script called pmd or pmd.bat and that’s it. The different utilities are implemented as sub commands. Under the hood, we use now Picocli. Using sub commands makes it easier, to unify the different command line flags, when there are overlapping options.
This means, that the CLI for starting the analysis looks now like pmd check. CPD can be started with pmd cpd, the rule designer can be started with pmd designer.
Additionally, a shell completion script can now be generated for Bash/Zsh. This is just a side effect of using Picocli, which provides this feature for free: source <(pmd generate-completion)
And finally, the CLI for the check command has been enhanced with a progress bar, which interactively displays the current progress of the analysis.
This change is of course a breaking change: If you used PMD on the command line, you now need to use the new command syntax. The overall, the CLI should make much more sense now. The differences are summarized in the Migration Guide for PMD 7: CLI Changes.
API rework
Another big task we planned for PMD 7 and mostly finished was the necessary API rework. PMD has been growing over the years and at some point, a cleanup is unavoidable. The main goal was, that we make a clear distinction between API and implementation and actually hide the implementation. This hopefully allows us, to change the implementation without breaking the API.
However, in order to do this refactoring, you first of all need to break the API, in order to separate API classes from implementation. That’s why such big changes can only be done in major releases. And since these changes are mostly done in pmd-core, they affect always all other modules and languages. This means, they must be done together.
During the development, we tried to provide a forward compatible way in PMD 6 already, like the new programmatic API to call PMD via PmdAnalysis. This is already available in PMD 6 and can be used and makes the migration to PMD 7 easier. However, this is not always possible, especially, when we moved or renamed classes to tidy up the package organization.
I think, with PMD 7, we made a big step forward in this area. The whole decision is written up in ADR 3 - API evolution principles and this remains an ongoing task: refining the API, documenting the API.
The detailed changes are too many, to list them all here. The full list of API changes since PMD 6.0.0 is in the Detailed Release Notes for PMD 7: API.
NodeStream
When writing rules for PMD, you currently write a visitor, which traverses the AST to find interesting nodes. Once you got hold of a node, you can also manually navigate the AST with Node#getChild(int) or Node#getParent(). PMD 6 provided additionally methods to find nodes of a specific type. However, if you wanted to navigate to the grand children, you also needed to add null checks and type checks.
With the new API around NodeStream, all this is made much easier. It is a powerful API to navigate trees, similar in usage to the Java 8 Stream API.
Here is an example, to find all method declarations, that have an explicit return null statement in it:
node.descendants(ASTMethodDeclaration.class)
.filter(it -> it.descendants(ASTReturnStatement.class)
.children(ASTNullLiteral.class).count() == 1)
.forEach(RuleContext::addViolation);
The equivalent XPath expression looks similar:
//MethodDeclaration[.//ReturnStatement[count(NullLiteral) = 1]]
This makes writing rules much easier without adding additional if conditions in case the return statements has no children at all etc.
A pipeline like shown here traverses the tree lazily, which is more efficient than traversing eagerly to put all descendants in a list. It is also much easier to change than the old imperative way.
To make this API as accessible as possible, the Node interface has been fitted with new methods producing node streams. Those methods replace previous tree traversal methods like Node#findDescendantsOfType. In all cases, they should be more efficient and more convenient.
See the javadoc of NodeStream for more details. Since this is a core API, it is supported by all languages out of the box.
Thanks to Clément Fournier (@oowekyala), who implemented this new API.
Statistics
Maybe it’s interesting to look back and wonder, what happened in the last 6 years? Correct: PMD 7 development officially started with commit 48d54b0a in June 2018, which is now 2105 days or 5.8 years in the past.
Since then:
- 5741 commits (excluding merges)
- 849 closed issues/PRs (Milestone 7.0.0)
- 46 individual commit authors
The code size in LOC between 6.55.0 and 7.0.0 is not so different - it appears, that 6.55.0 was even bigger. Looking at older versions, 6 started out smaller than 5 and got bigger over the time.
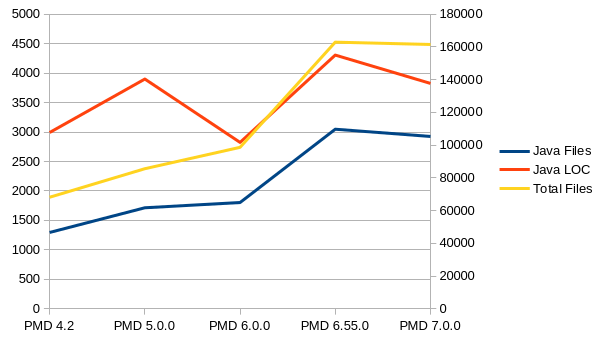
In summary, it might seem that PMD 7 is “only” 138k lines big, while PMD 6 was 155k lines of uncommented java code. Does PMD 7 more with less code? Maybe, maybe not. If considering not only Java but also Kotlin code, then it’s a bit different: Kotlin is used much more in PMD 7 for the test framework code and also in the Apex module to build the AST. Kotlin code in PMD 7 adds another 18k lines of code, and that makes PMD 6 and PMD 7 almost equal (if you really want to compare the code size in this way).
Cloc also shows, we have a ton of XML code lines. These are most likely our rule tests: In PMD 7, we have in total 122k lines of XML code.
The program Git of Theseus can generate interesting graphs that show how the code added in different years changed:
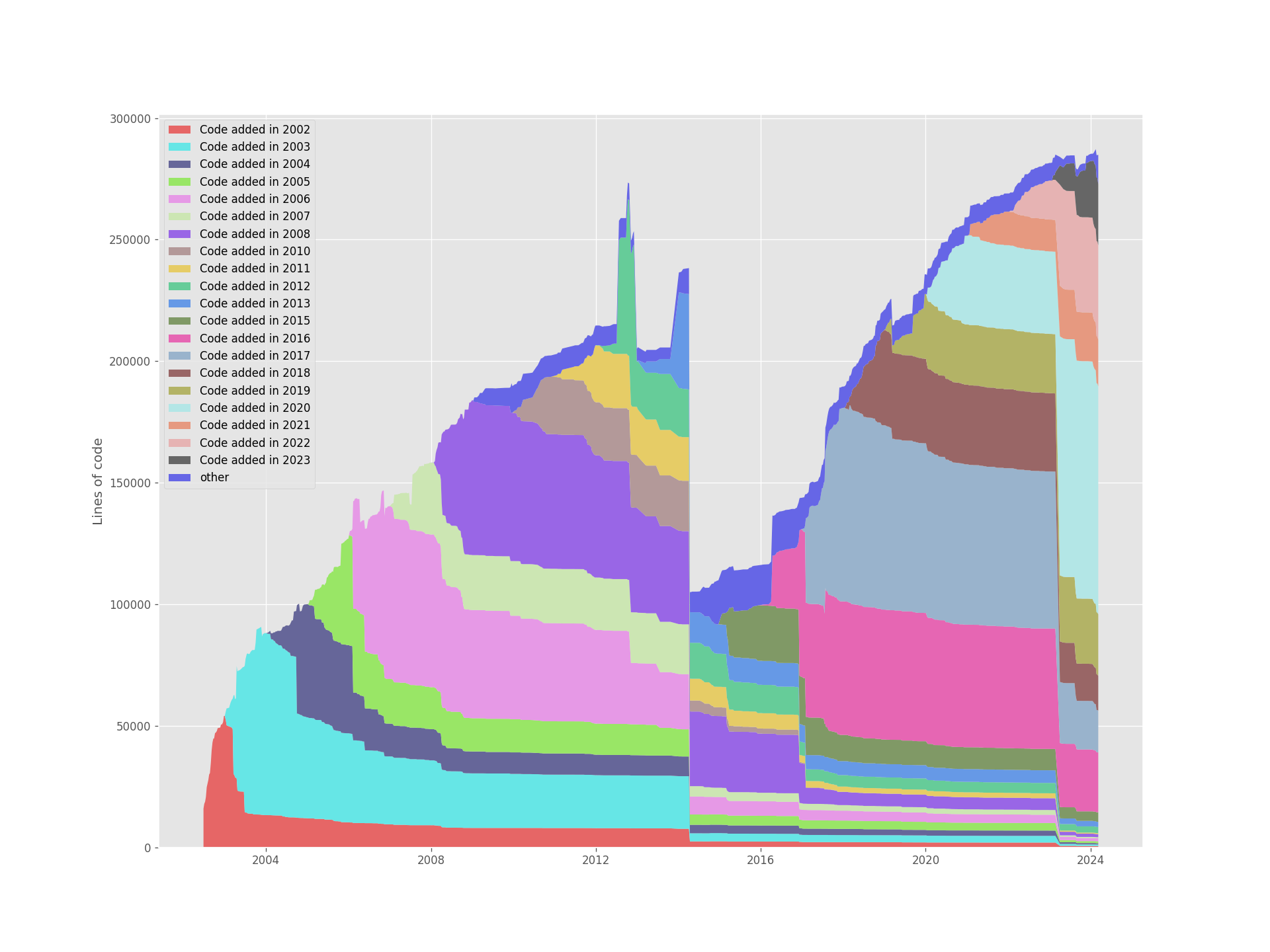
You can see a couple of big changes: between 2012 and 2016. I think, that is caused by the switch from SVN to Git - when many things were moved out of the monorepo. The next is probably PMD 6 release, which happened end of 2017. And the last big change is probably PMD 7.
This is now the seventh major release of PMD. The first release of PMD was done on 2002-11-04, about half a year after the first commit. In average, every 3 years a new PMD release was published.
How to upgrade / how to use?
First step is obviously to download PMD. The binary is available through the PMD Releases page on GitHub.
Follow the installation instructions, which basically means: extracting the ZIP archive, and run it. E.g.
pmd-bin-7.0.0/bin/pmd check -d path_to_sources -R rulesets/java/quickstart.xml -f txt -r pmd-report.txt
You’ll notice, that we now have a progress bar, showing how many files have already been processed.
If you use Maven or Gradle as build tools, there are special plugins. See the examples in our documentation for the Maven PMD Plugin and Gradle PMD Integration.
ℹ️ Note: For maven-pmd-plugin to use with PMD 7.0.0, the special module net.sourceforge.pmd:pmd-compat6 is required. See Using PMD 7 with maven-pmd-plugin. In order to use Gradle with PMD 7.0.0, at least Gradle 8.6 is required. The you can simply set the toolVersion configuration.
If you are switching from PMD 6.x to PMD 7, then there are a couple of things to consider:
- some (deprecated) rules might have been entirely removed
- some rule properties might have changed, especially properties, which take multiple values: the one and only delimiter is now always a comma. The pipe is not supported anymore.
- there are some new rules, you might want to use
If you have written custom rules, the changes might be more involved, due to some API changes and refactoring we did in PMD.
In any case, you can follow the Migration Guide for PMD 7 which should cover any possible issue.
Next steps in PMD
As always, software is never finished. And especially for PMD 7, we needed to postpone some of our initial, ambitious ideas, so that PMD 7 actually could be released eventually. That means: after the release is before the next release.
The coarse plan is to reestablish our time based monthly releases again. I expect the first releases mostly to contain bug fixes. But this really depends on the contributions.
Before changing the API, we should really make sure, we have some tool in place, that warns us, if we are about to change anything in an incompatible way. There are some tools, like japicmp. Ideally, we would be very careful when changing anything in pmd-core now.
The are other topics, that can be tackled now as well: Multi file analysis which most likely requires some kind of multi stage analysis. Streamlining our CI builds, which are on GitHub Actions, so that it’s easier to see what failed, when it fails. And maybe provide a nightly build directly on GitHub Releases. Improve the rule documentation, which might require to change the ruleset xml format. There are lots of ideas and possibilities.
An interesting idea would be to make it easier to try out PMD to see, whether its useful for a specific project. Or to simply reproduce any problem. Maybe you have seen javaalmanac.io? There you can simply try out every java version online. Maybe something like this would be useful for PMD itself? Kind of a web interface to run PMD and show the found violations.
In any case, we an issue tracker already full of ideas to work on…
Call to action
Now it’s your turn: Use the new version, report any issues you find and any features you are missing. Let us know, what you think. Either through an issue on GitHub or through a question on the discussions page. What would you like to have fixed in the next version? Which feature would you like to have added to PMD? How can you contribute?
ℹ️ This blog is crossposted on:
Comments
No comments yet.Leave a comment
Your email address will not be published. Required fields are marked *. All comments are held for moderation to avoid spam and abuse.